
Нейронна мережа – один із напрямків штучного інтелекту, мета якого змоделювати аналітичні механізми, що здійснюються людським мозком. Завдання, які вирішує типова нейромережа – класифікація, передбачення та розпізнавання. Нейросети здатні самостійно навчатися і розвиватися, будуючи свій досвід на помилках.
Нейросети це послідовність нейронів, з’єднаних між собою синапсами. Структура нейронної мережі прийшла у світ програмування прямо з біології. Завдяки такій структурі машина знаходить здатність аналізувати і навіть запам’ятовувати різну інформацію. Також нейронні мережі здатні як аналізувати вхідну інформацію, а й відтворювати її з власної пам’яті.
Іншими словами, нейромережа це машинна інтерпретація мозку людини, в якому знаходяться мільйони нейронів, що передають інформацію у вигляді електричних імпульсів.
Зміст
Історія створення нейронних мереж
Яка ж історія розвитку нейронних мереж у науці та техніці? Вона бере свій початок з появою перших комп’ютерів або ЕОМ (електронно-обчислювальна машина), як їх називали в ті часи. Так ще наприкінці 1940-х років Дональд Хебб розробив механізм нейронної мережі, чим заклав правила навчання ЕОМ, цих «протокомп’ютерів».
Подальша хронологія подій була такою :
- У 1954 року відбувається перше практичне використання нейронних мереж у роботі ЕОМ.
- У 1958 році Франком Розенблатом розроблено алгоритм розпізнавання образів та математична анотація до нього.
- У 1960-х роках інтерес до розробки нейронних мереж дещо згас через слабкі потужності комп’ютерів того часу.
- І знову відродився вже у 1980-х роках, саме в цей період з’являється система із механізмом зворотного зв’язку, розробляються алгоритми самонавчання.
- До 2000 року потужності комп’ютерів виросли настільки, що змогли втілити найсміливіші мрії вчених минулого. У цей час з’являються програми розпізнавання голосу, комп’ютерного зору та багато іншого.
GeekUniversity спільно з Mail.ru Group відкрили перший в Росії факультет Штучного інтелекту , який викладає нейронні мережі. Для навчання достатньо шкільних знань. Програма включає всі необхідні ресурси та інструменти + ціла програма з вищої математики. Чи не абстрактна, як у звичайних вузах, а побудована на практиці. Навчання познайомить вас з технологіями машинного навчання та нейронними мережами, навчить вирішувати справжні бізнес-завдання.
Як працюють нейронні мережі?
Штучна нейронна мережа – сукупність нейронів, що взаємодіють один з одним. Вони здатні приймати, обробляти та створювати дані. Це так само складно уявити, як і роботу людського мозку. Нейронна мережа в нашому мозку працює для того, щоб ви могли це прочитати: наші нейрони розпізнають літери і складають їх у слова.
Нейронна мережа включає кілька шарів нейронів, кожен з яких відповідає за розпізнавання конкретного критерію: форми, кольору, розміру, текстури, звуку, гучності і т.д.
Рік від року в результаті мільйонів експериментів та тонн обчислень до найпростішої мережі додавалися нові та нові верстви нейронів. Вони працюють по черзі. Наприклад, перший визначає, чи квадрат не квадрат, другий розуміє, квадрат червоний чи ні, третій обчислює розмір квадрата і так далі. Чи не квадрати, не червоні і невідповідного розміру фігури потрапляють у нові групи нейронів і досліджуються вже ними.
Навіщо потрібні нейромережі?
Нейронні мережі використовуються для вирішення складних завдань, які вимагають аналітичних обчислень подібних до тих, що робить людський мозок. Найпоширенішими застосуваннями нейронних мереж є:
- Класифікація – розподіл даних за параметрами. Наприклад, на вхід надається набір людей і потрібно вирішити, кому з них давати кредит, а кому ні. Цю роботу може зробити нейронна мережа, аналізуючи таку інформацію як: вік, платоспроможність, кредитна історія тощо.
- Пророцтво — можливість передбачати наступний крок. Наприклад, зростання чи падіння акцій, ґрунтуючись на ситуації на фондовому ринку.
- Розпізнавання – нині, найширше застосування нейронних мереж. Використовується в Google, коли ви шукаєте фото або камери телефонів, коли воно визначає положення вашої особи і виділяє його і багато іншого.
Область застосування штучних нейронних мереж з кожним роком дедалі більше розширюється, на сьогоднішній день вони використовуються у таких сферах як:
- Машинне навчання (machine learning) , що є різновидом штучного інтелекту. У його основі лежить навчання ІІ з прикладу мільйонів однотипних завдань. В наш час машинне навчання активно впроваджують пошукові системи Google, Яндекс, Бінг, Байду. Так на основі мільйонів пошукових запитів, які ми щодня вводимо в Гуглі, їх алгоритми вчаться показувати нам найбільш релевантну видачу, щоб ми могли знайти саме те, що шукаємо.
- У роботехніці нейронні мережі застосовуються у виробленні численних алгоритмів для металевих «мозків» роботів.
- Архітектори комп’ютерних систем користуються нейронними мережами на вирішення проблеми паралельних обчислень.
- За допомогою нейронних мереж математики можуть розв’язувати різні складні математичні завдання.
Тепер, щоб зрозуміти, як працюють нейронні мережі, давайте поглянемо на її складові та їх параметри.
Що таке нейрон?
Нейрон – це обчислювальна одиниця, яка отримує інформацію, здійснює над нею прості обчислення і передає її далі. Вони діляться на три основні типи: вхідний (синій), прихований (червоний) та вихідний (зелений):
Також є нейрон зміщення та контекстний нейрон. У разі, коли нейромережа складається з великої кількості нейронів, вводять термін шару. Відповідно, є вхідний шар, який отримує інформацію, n прихованих шарів (зазвичай їх не більше 3), які її обробляють та вихідний шар, який виводить результат.
У кожного з нейронів є 2 основні параметри:
- вхідні дані (input data),
- вихідні дані (output data).
Що стосується вхідного нейрона: input=output. В інших, в поле input потрапляє сумарна інформація всіх нейронів з попереднього шару, після чого вона нормалізується за допомогою функції активації (поки що просто представимо її f(x)) і потрапляє в поле output.
Важливо пам’ятати, що нейрони оперують числами у діапазоні [0,1] або [-1,1]. А як же ви запитаєте, тоді обробляти числа, які виходять з даного діапазону? На даному етапі найпростіша відповідь – це розділити 1 на це число. Цей процес називається нормалізацією, і він часто використовується в нейронних мережах. Докладніше про це трохи пізніше.
Що таке синапс?
Синапс це зв’язок між двома нейронами. У синапсів є один параметр – вага. Завдяки йому вхідна інформація змінюється, коли передається від одного нейрона до іншого. Допустимо, є 3 нейрони, які передають інформацію наступному. Тоді у нас є 3 ваги, які відповідають кожному з цих нейронів. У того нейрона, у якого вага буде більшою, та інформація і буде домінуючою в наступному нейроні (приклад – змішання кольорів).
Насправді, сукупність терезів нейронної мережі або матриця терезів – це своєрідний мозок всієї системи. Саме завдяки цим вагам, вхідна інформація обробляється та перетворюється на результат.
Важливо пам’ятати, що під час ініціалізації нейронної мережі ваги розставляються у випадковому порядку.
Біологічна основа нейрозв’язків
У мозку є нейрони. Їх близько 86 мільярдів. Нейрон – це клітина, сполучена з іншими такими клітинами. Клітини з’єднані один з одним відростками. Все це разом нагадує своєрідну мережу. Ось вам і нейронна мережа. Кожна клітина отримує сигнали з інших клітин. Далі обробляє їх і сама надсилає сигнал іншим клітинам.
Простіше кажучи, нейрон отримує сигнал (інформацію), обробляє його (щось там вирішує, думає) і відправляє свою відповідь далі. Стрілки зображають зв’язки-відростки якими передається інформація:
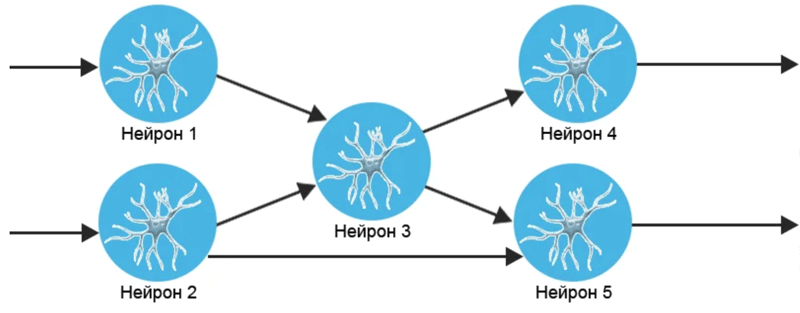
Ось так передаючи один одному сигнали, нейронна мережа приходить до будь-якого рішення. А ми думали, що ми одноосібно все вирішуємо! Ні, наше рішення — результат колективної роботи мільярда нейронів.
На моєму малюнку стрілки позначають зв’язки нейронів. Зв’язки бувають різні. Наприклад, стрілка внизу між нейроном 2 і 5 довга. І значить сигнал від нейрона 2 до нейрона 5 буде довше йти, ніж сигнал від нейрона 3 де стрілка вдвічі коротше. Та й взагалі сигнал може загаснути та прийти слабким. У біології багато всього цікавого.
Але розглядати все це — як там думає нейрон, чи загасне сигнал, коли він прийде чи не прийде в ІТ не стали. А що голову морочити? І просто збудували спрощену модель.
У цій моделі можна виділити дві основні складові :
- Алгоритм . У біології нейрон думає. У програмуванні “думання” замінюється алгоритмом – тобто набором команд. Наприклад – якщо на вхід прийшла 1 відправ 0. Ось і всі “мозки” нашого нейрона.
- Вага рішення . Усі зв’язки, згасання тощо. вирішили замінити “вагою”. Вага це як сила рішення, його важливість. Це просто величина, найчастіше число. Наш нейрон приходить рішення з певною вагою, наш нейрон приходить число. І якщо воно більше іншого числа, що прийшло, то воно важливіше. Це як приклад.
Отже: є алгоритм і є вага рішення. Це все, що потрібно для побудови найпростішої нейромережі.
Штучна нейронна мережа
Нейронна мережа — спроба за допомогою математичних моделей відтворити роботу людського мозку для створення машин, які мають штучний інтелект .
Штучна нейронна мережа зазвичай навчається з учителем. Це означає наявність навчального набору (датасету), який містить приклади з істинними значеннями: тегами, класами, показниками.
Наприклад, якщо ви хочете створити нейромережу для оцінки тональності тексту, датасет буде список пропозицій з відповідними кожному емоційними оцінками. Тональність тексту визначають ознаки (слова, фрази, структура речення), які надають негативного або позитивного забарвлення. Вага ознак у підсумковій оцінці тональності тексту (позитивний, негативний, нейтральний) залежить від математичної функції, яка обчислюється під час навчання нейронної мережі.
Раніше люди генерували ознаки вручну. Чим більше ознак і точніше підібрані ваги, тим точніше відповідь. Нейронна мережа автоматизувала цей процес:
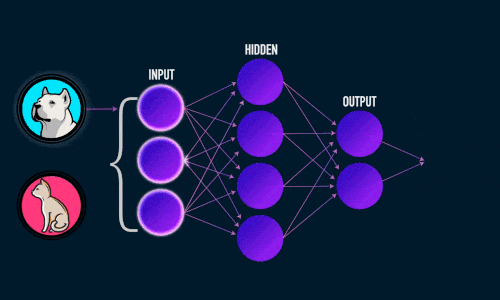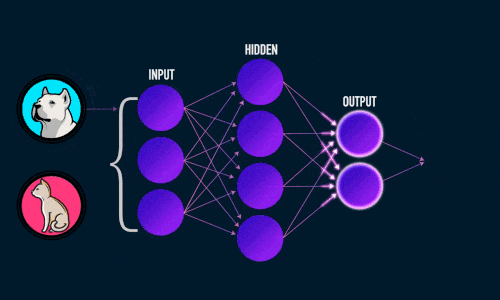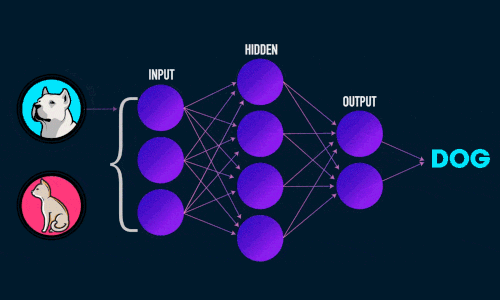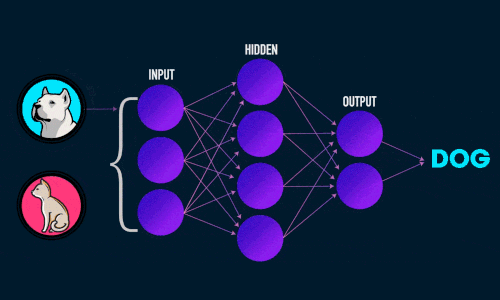
Штучна нейронна мережа складається з трьох компонентів :
- Вхідний шар;
- Приховані (обчислювальні) шари;
- Вихідний шар.
Навчання таких нейромереж відбувається у два етапи :
- Пряме поширення помилки;
- Зворотне поширення помилки.
Під час прямого поширення помилки робиться прогноз відповіді. При зворотному поширенні помилка між фактичною відповіддю та передбаченим мінімізується.
Для більш глибокого вивчення радимо до перегляду 2 відео з TED Talks: Відео 1 , Відео 2 (відео-ролики англійською мовою).
Види та класифікація нейронних мереж
За період розвитку нейронні мережі поділилися на безліч типів, які переплітаються між собою в різних завданнях. На даний момент складно класифікувати будь-яку мережу лише за однією ознакою. Це можна зробити за принципом застосування, типом вхідної інформації, характером навчання, характером зв’язків, сферою застосування.
| Нейронна мережа | Принцип застосування | Навчання з учителем (+) або без (-) або змішане (с) | Сфера застосування |
| Перцептрон Розенблатта | Розпізнання образів, прийняття рішень, прогнозування, апроксимація, аналіз даних | + | Практично будь-яка сфера застосування, крім оптимізації інформації |
| Хопфілда | Стиснення даних та асоціативна пам’ять | – | Будова комп’ютерних систем |
| Кохонена | Кластеризація, стиснення даних, аналіз даних, оптимізація | – | Фінанси, бази даних |
| Радіально-базових функцій (RBF-мережа) | Прийняття рішень та управління, апроксимація, прогнозування | з | Управлінські структури, нейроуправління |
| Згорткова | Розпізнання образів | + | Обробка графічних даних |
| Імпульсна | Прийняття рішення, розпізнавання образів, аналіз даних | з | Протезування, робототехніка, телекомунікації, комп’ютерний зір |
Що таке навчання з учителем, написано в наступному розділі. Кожна мережа має свої характеристики, які можна застосовувати у тому чи іншому випадку. Розглянемо докладніше два типи мереж, які з безлічі похідних типів нейромереж є першоджерелами.
Згорткові
Один з найпопулярніших типів мережі, який часто використовується для розпізнавання тієї чи іншої інформації у фотографіях та відео, обробці мови, системах для рекомендацій.
Основні характеристики :
- Відмінна масштабованість – проводять розпізнання образів будь-якого дозволу (яке б воно не було велике).
- Використання об’ємних тривимірних нейронів – усередині шару, нейрони пов’язані малим полем, іменовані рецептивним шаром.
- Механізм просторової локалізації – сусідні шари нейронів пов’язані таким механізмом, за рахунок чого забезпечується робота нелінійних фільтрів та охоплення дедалі більшої кількості пікселів графічного зображення.
Ідея складної системи цього типу нейромережі виникла при ретельному вивченні зорової кори, яка у великих півкулях мозку відповідає за обробку візуальної складової. Основний критерій вибору користь згорткового типу – вона у складі технологій глибокого навчання. Подібний тип з перцептроном, але різниця в тому, що тут використовується обмежена матриця ваг, що зсувається по шару, що обробляється, замість повнозв’язкової нейронної мережі.
Рекурентні
Цей тип нейромережі, де зв’язки між елементами можуть обробляти серії різних подій у часі або працювати з послідовними ланцюжками в просторі. Такий тип часто застосовують там, де щось розбите на шматки. Наприклад, розпізнавання мови або рукописного тексту. Від неї походить безліч видів мереж, зокрема Хопфілда, Елмана та Джордана.
Навчання нейронної мережі
Один з основних і найважливіший критерій – можливість навчання нейромережі. У цілому нині, нейромережа – це сукупність нейронів, якими проходить сигнал. Якщо подати його на вхід, пройшовши через тисячі нейронів, на виході вийде невідомо що. Для перетворення необхідно змінювати параметри мережі, щоб на виході вийшли потрібні результати.
Вхідний сигнал змінити не можна, суматор виконує функцію підсумовування та змінити щось у ньому або вивести із системи не вийде, оскільки це перестане бути нейромережею. Залишається одне – використовувати коефіцієнти або корелюючі функції та застосовувати їх на ваги зв’язків. І тут можна дати визначення навчання нейронної мережі – це пошук набору вагових коефіцієнтів, які за проходженні через суматор дозволять отримати потрібний сигнал.
Таку концепцію застосовує наш мозок. Замість терезів у ньому використовуються синопси, що дозволяють посилювати або робити згасання вхідного сигналу. Людина навчається завдяки зміні синапсів при проходженні електрохімічного імпульсу в нейромережі головного мозку.
Але є один нюанс. Якщо ж задати вручну коефіцієнти ваги, то нейромережа запам’ятає правильний вихідний сигнал. При цьому висновок інформації буде миттєвим і може здатися, що нейромережа змогла швидко навчитися. І варто трохи змінити вхідний сигнал як на виході з’являться неправильні, не логічні відповіді.
Тому замість вказівки конкретних коефіцієнтів для одного вхідного сигналу можна створити узагальнюючі параметри за допомогою вибірки.
За допомогою такої вибірки можна навчати мережу, щоб вона видавала коректні результати. У цьому моменті можна розділити навчання нейромережі на навчання з учителем і без вчителя.
Навчання з учителем
Навчання в такий спосіб має на увазі концепцію: даєте вибірку вхідних сигналів нейромережі, отримуєте вихідні та порівнюєте з готовим рішенням.
Як готувати такі вибірки :
- Для розпізнавання осіб створити вибірку із 5000-10000 фотографій (вхід) та самостійно вказати, які містять особи людей (вихід, правильний сигнал).
- Для прогнозування зростання чи падіння акцій, вибірка проводиться у разі аналізу даних минулих десятиліть. Вхідними сигналами може бути як стан ринку загалом, і конкретні дні.
Вчителем не обов’язково є людина. Мережа потрібно тренувати сотнями та тисячами годин, тому у 99% випадків тренуванням займається комп’ютерна програма.
Навчання без вчителя
Концепція полягає в тому, що робиться вибірка вхідних сигналів, але правильних відповідей на виході ви не можете знати.
Як відбувається навчання? Теоретично і практично, нейромережа починає кластеризацію, тобто визначає класи поданих вхідних сигналів. Потім вона видає сигнали різних типів, що відповідають за вхідні об’єкти.
Згорткова нейронна мережа
Згорткова нейронна мережа (СНС, CNN) – спеціальна архітектура штучних нейронних мереж, запропонована Яном Лекуном і націлена на ефективне розпізнавання образів. Даній архітектурі вдається набагато точніше розпізнавати об’єкти на зображеннях, оскільки, на відміну багатошарового персептрона, враховується двомірна топологія зображення. При цьому згорткові мережі стійкі до невеликих зсувів, змін масштабу та поворотів об’єктів на вхідних зображеннях. Багато в чому, тому архітектури, засновані на сверточних мережах, досі займають перші місця у змаганнях з розпізнавання образів, як, наприклад, ImageNet .
Згорткова нейронна мережа є основним інструментом для класифікації та розпізнавання об’єктів, осіб на фотографіях, розпізнавання мови. Є безліч варіантів застосування CNN, такі як Deep Convolutional Neural Network (DCNN), Region-CNN (R-CNN), Fully Convolutional Neural Networks (FCNN), Mask R-CNN та інші.
CNN на сьогодні – “робоча конячка” в галузі нейронних мереж. Використовується переважно для вирішення завдань комп’ютерного зору, хоча може застосовуватися також для роботи з аудіо та будь-якими даними, які можна подати у вигляді матриць.
Особливості роботи згорткових мереж
Нам відомо, що нейронні мережі хороші у розпізнаванні зображень. Причому хороша точність досягається і звичайними мережами прямого поширення, проте, коли мова заходить для обробки зображень з великою кількістю пікселів, то кількість параметрів для нейронної мережі багаторазово збільшується. Причому настільки, що час, що витрачається на їхнє навчання, стає неймовірно більшим.
Так, якщо потрібно працювати з кольоровими зображеннями розміром 64х64, то для кожного нейрона першого шару повнозв’язкової мережі потрібно 64 64 3 = 12288 параметрів, а якщо мережа повинна розпізнавати зображення 1000х1000, то вхідних параметрів буде вже 3 млн! А крім вхідного шару є й інші шари, на яких найчастіше число нейронів перевищує кількість нейронів на вхідному шарі, через що 3 млн запросто перетворюються на трильйони! Така кількість параметрів просто неможливо розрахувати швидко через недостатньо обчислювальних потужностей комп’ютерів.
Головною особливістю згорткових мереж є те, що вони працюють саме із зображеннями, а тому можна виділити особливості, властиві саме їм. Багатошарові персептрони працюють з векторами, тому для них немає жодної різниці, чи знаходяться якісь точки поруч або на протилежних кінцях, так як всі точки рівнозначні і вважаються абсолютно однаковим чином. Зображення ж мають локальну зв’язність. Наприклад, якщо йдеться про зображення людських осіб, то цілком логічно очікувати, що точки основних частин особи будуть поруч, а не розрізнено розташовуватися на зображенні. Тому потрібно знайти ефективніші алгоритми для роботи із зображеннями і ними виявилися згорткові мережі.
На відміну від мереж прямого поширення, що працюють з даними у вигляді векторів, згорткові мережі працюють із зображеннями у вигляді тензорів. Тензор — це 3D масиви чисел, або, простіше кажучи, масиви матриць чисел.
Зображення в комп’ютері відображаються у вигляді пікселів, а кожен піксель – це значення інтенсивності відповідних каналів. При цьому інтенсивність кожного каналу описується цілим числом від 0 до 255.
Найчастіше використовуються кольорові зображення, які складаються з RGB пікселів – пікселів, що містять яскравості по трьох каналах: червоному, зеленому та синьому. Різні комбінації цих кольорів дозволяють створити будь-який із кольорів всього спектра. Саме тому цілком логічно використовувати саме тензор для представлення зображень: кожна матриця тензора відповідає за інтенсивність свого каналу, а сукупність всіх матриць описує все зображення.
З чого складаються згорткові сітки?
Згорткові нейронні мережі складаються з базових блоків, завдяки чому їх можна збирати як конструктор, додаючи шар за шаром та отримуючи все потужніші архітектури. Основними блоками згорткових нейронних мереж є згорткові шари, шари підвиборки (пулінгу), шари активації та пов’язані шари.
Так, наприклад, LeNet5 – одна з перших згорткових мереж, яка перемогла в ImageNet, складалася з 7 шарів: шар згортки, шар пулінгу, ще один шар згортки ще один шар пулінгу і тришарова повнозв’язна нейронна мережа.
Згортковий шар
Згортковий шар нейронної мережі є застосуванням операції згортки до виходів з попереднього шару, де ваги ядра згортки є навчальними параметрами. Ще один навчається вага використовується як константного зсуву (англ. bias). При цьому є кілька важливих деталей:
- В одному згортковому шарі може бути кілька згорток. В цьому випадку для кожного згортки на виході вийде зображення. Наприклад, якщо вхід мав розмірність w×hw×h, а шарі було nn згорток з ядром розмірності kx×kykx×ky, вихід буде мати розмірність n×(w−kx+1)×(h−ky+1)n ×(w−kx+1)×(h−ky+1);
- Ядра згортки можуть бути тривимірними. Згортка тривимірного входу з тривимірним ядром відбувається аналогічно, просто скалярне твір вважається ще й у всіх шарах зображення. Наприклад, для усереднення інформації про кольори вихідного зображення, на першому шарі можна використовувати згортку розмірності 3×w×h3×w×h. На виході такого шару буде вже одне зображення (замість трьох);
- Можна помітити, що застосування операції згортки зменшує зображення. Також пікселі, які знаходяться на межі зображення, беруть участь у меншій кількості згорток, ніж внутрішні. У зв’язку з цим у згорткових шарах використовується доповнення зображення (padding). Виходи з попереднього шару доповнюються пікселями так, щоб після згортки зберігся розмір зображення. Такі згортки називають однаковими (англ. same convolution), а згортки без доповнення зображення називаються правильними (англ. valid convolution). Серед способів, якими можна заповнити нові пікселі, можна виділити такі:
- zero shift: 00[ABC]00;
- border extension: AA[ABC]CC;
- mirror shift: BA[ABC]CB;
- cyclic shift: BC[ABC]AB.
- Ще одним параметром згорткового шару є зсув (англ. stride). Хоча зазвичай згортка застосовується підряд для кожного пікселя, іноді використовується зрушення, відмінне від одиниці – скалярний твір вважається не з усіма можливими положеннями ядра, а тільки з положеннями, кратними деякому зсуву ss. Тоді, якщо вхід мав розмірність w×hw×h, а ядро згортки мало розмірність kx×kykx×ky та використовувався зсув ss, то вихід матиме розмірність ⌊w−kxs+1⌋×⌊h−kys+1⌋⌊w −kxs+1 ×⌊h−kys+1⌋.
Пулінговий шар
Пулінговий шар покликаний знижувати розмірність зображення. Вихідне зображення ділиться на блоки розміром w×hw×h і кожного блоку обчислюється деяка функція. Найчастіше використовується функція максимуму (англ. max pooling) або (зваженого) середнього (англ. (weighted) average pooling). Навчальних параметрів цього шару немає.
Основні цілі пулінгового шару :
- зменшення зображення, щоб наступні згортки оперували над більшою областю вихідного зображення;
- збільшення інваріантності виходу мережі стосовно малого перенесення входу;
- прискорення обчислень.
Inception module
Inception module – це спеціальний шар нейронної мережі, який був запропонований у роботі [2], в якій була представлена мережа GoogLeNet. Основна мета цього модуля ось у чому. Автори припустили, що кожен елемент попереднього шару відповідає певній області вихідного зображення. Кожна згортка за такими елементами збільшуватиме область вихідного зображення, поки елементи на останніх шарах не будуть відповідати всьому зображенню повністю. Однак, якщо з якогось моменту всі згортки стануть розміром 1×11×1, то не знайдеться елементів, які б покривали все вихідне зображення, тому було б неможливо знаходити великі ознаки на зображенні.
Щоб вирішити цю проблему, автори запропонували так званий inception module – конкатенацію виходів для згорток розміру 1x11x1, 3x33x3, 5x55x5, а також операції max pooling’а з ядром 3x33x3.
На жаль, подібний наївний підхід (naive inception module) призводить до різкого збільшення шарів зображення, що не дозволяє побудувати з його використанням глибоку нейронну мережу. Для цього автори запропонували використовувати модифікований inception module з додатковим зменшенням розмірності – додатково до кожного фільтру вони додали шар згортки 1x11x1, який хлопає всі шари зображення в один. Це дозволяє зберегти малу кількість шарів із збереженням корисної інформації про зображення.
Residual block
Двома серйозними проблемами в навчанні глибоких нейронних мереж є градієнт, що зникає (англ. vanishing gradient) і градієнт, що вибухає (англ. exploding gradient). Вони виникають через те, що при диференціюванні за ланцюговим правилом, до глибоких шарів нейронної мережі доходить дуже маленька величина градієнта (через багаторазове примноження на невеликі величини на попередніх шарах). Для боротьби з цією проблемою було запропоновано так званий residual block.
Ідея полягає в тому, щоб взяти пару шарів (наприклад, згорткових), і додати додатковий зв’язок, який проходить повз ці шари. Нехай z(k) — вихід k шару до застосування функції активації, а a(k) — вихід після. Тоді residual block виконуватиме наступне перетворення: a(k+2)=g(z(k+2)+a(k)), де g — функція активації.
Насправді, така нейронна мережа вчиться пророкувати функцію F(x)−x, замість функції F(x), яку спочатку потрібно було пророкувати. Для компенсації цієї різниці і вводиться це замикаюче з’єднання (англ. shortcut connection), яке додає недостатній x до функції.
Припущення авторів, які запропонували residual block, у тому, що таку різницеву функцію простіше навчати, ніж вихідну. Якщо розглядати крайні випадки, то якщо F(x)=x, таку мережу навчити нулю завжди можливо, на відміну навчання безлічі нелінійних шарів лінійному перетворенню.


